.png?type=webp)
Linear Regression learn from scratch and also implement
7 December, 2022
0
0
0
Contributors
.jpeg?type=webp)
1.
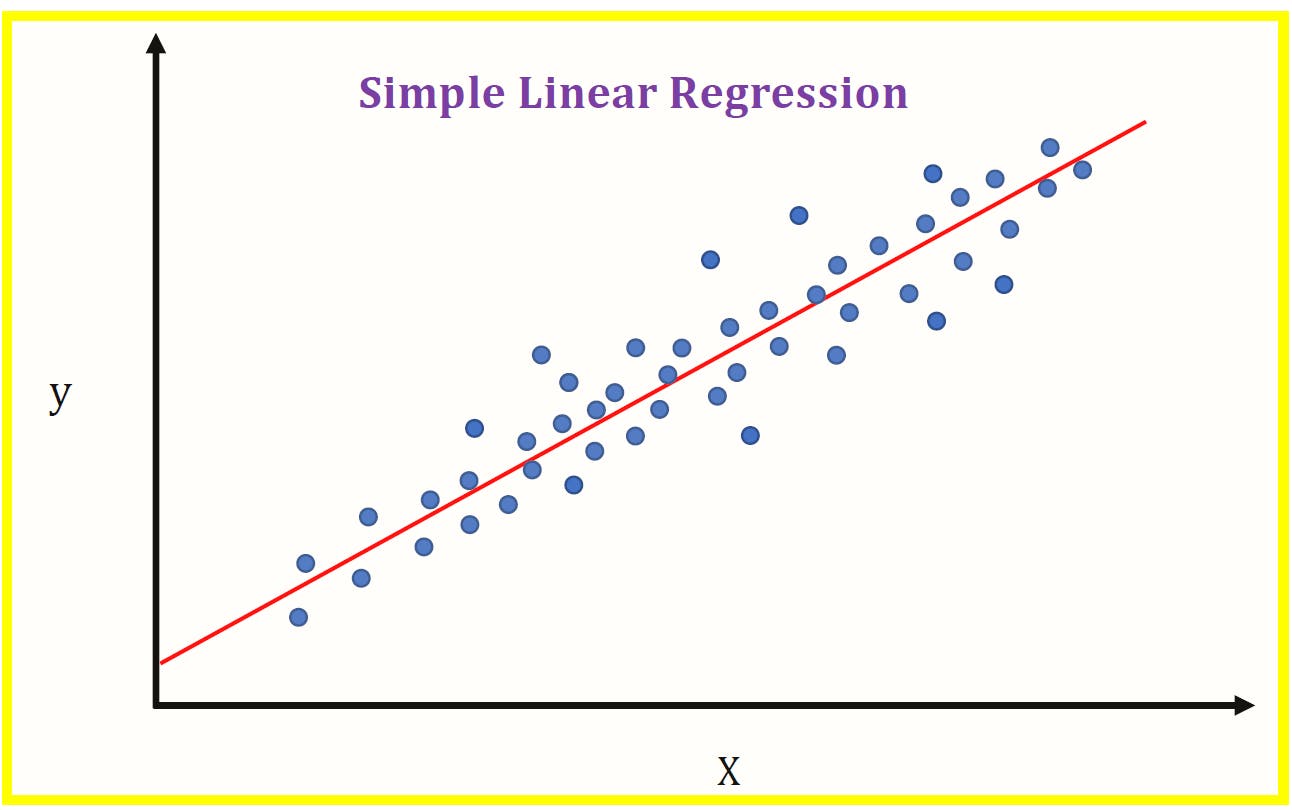
First we randomly take the value of the parameter and form a line with the parameter
2.
In the second step we try to find an error or residual which
Error= Actual - Predicted
3.
In the third step we try to change the parameter value such that the line forming with parameter will be the best fit line that fits the data linearly with less error.
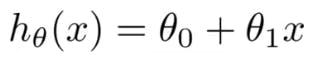
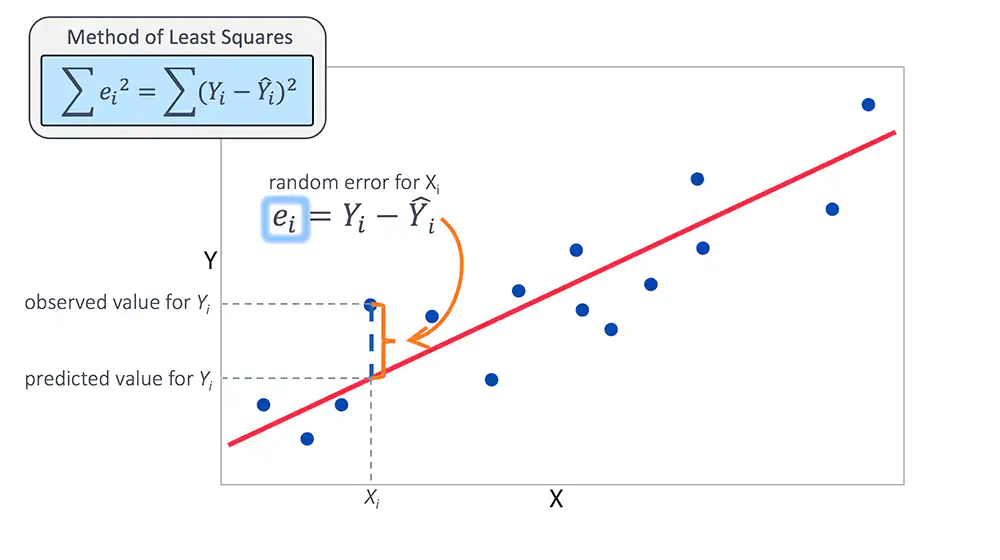
1.
Mean squared error
2.
Mean Absolute error
3.
Root Mean squared error
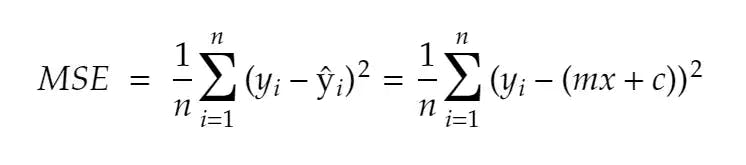
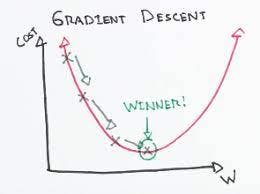
1.
To update 𝜽0 and 𝜽1 we take gradients from the cost function. To find these gradients, we take partial derivatives with respect to 𝜽0 and 𝜽1 The partial derivatives are the gradients and they are used to update the values of 𝜽0 and 𝜽1 .
2.
The number of steps taken is the learning rate (𝛼 below). This decides on how fast the algorithm converges to the minima. Alpha is the learning rate which is a hyperparameter that you must specify. A smaller learning rate could get you closer to the minima but takes more time to reach the minima. A larger learning rate converges sooner but there is a chance that you could overshoot the minima.