
Web Scraping Tutorial: Python and BeautifulSoup
8 September, 2020
0
0
0
Contributors

Introduction
Web scraping lets us quickly scan through a webpage, extract information, and store it for later use. In this tutorial, you will (hopefully) learn how to access and parse html contents using Python 3, BeautifulSoup and requests libraries. I will be using Sublime Text (https://www.sublimetext.com/3) and Terminal. You can use any text editor (IDLE, Visual Studio, Jupyter Notebook).
From IMDb Top 25 Movies of All Time (www.imdb.com/list/ls024149810/), we will extract the movie titles, genres, ratings, and runtimes.
Prerequisites (If not already installed)
- Install Python version 3.7 (https://www.python.org/downloads/release/python-370/)
- Install BeautifulSoup4 and requests libraries
Installing Dependencies
The requests library sends a HTTP request to the web server, so you can download html contents from a webpage. The BeautifulSoup library lets you parse through html. These libraries aren’t included in Python’s standard library, so install them using pip. Launch the Terminal and enter the following pip command:
pip install requests bs4Getting Started
Create a new python file top_movies.py and save it onto your Desktop. To run files on Sublime, enter the following command into the Terminal.
python ~/Desktop/top_movies.pyImport the required libraries into Sublime (or any text editor) to connect to the webpage.
import requests
from bs4 import BeautifulSoupPass the url to requests.get(). The get()method allows users to download and access the html.
url = ‘https://www.imdb.com/list/ls024149810/'
r = requests.get(url)*Tip: If the following command returns 200, then you have successfully accessed the webpage*
print(r.status_code)Creating a BeautifulSoup object will allow us to parse through the html contents.
soup = BeautifulSoup(r.content, ‘html.parser’)Inspecting and extracting data
Understanding the basics of html will allow you to be successful when web scraping. If you are new to html, check out w3schools (https://www.w3schools.com/html/html_intro.asp)
To view the source code, right-click anywhere on the webpage and click on “Inspect Element” (Safari browser). This allows you to see all the images, links, and CSS codes that form the site.

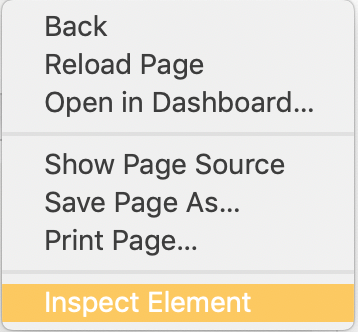
You should see this console pop-up.


The red arrow above points to a button that lets you manually locate individual elements to the cooresponding code and highlights it in the console.




Movie Titles
When you click around the console, you will discover that each tag contains a specific string or document. Each movie item is contained in <div> tags and is defined in theclass="lister-item-content".

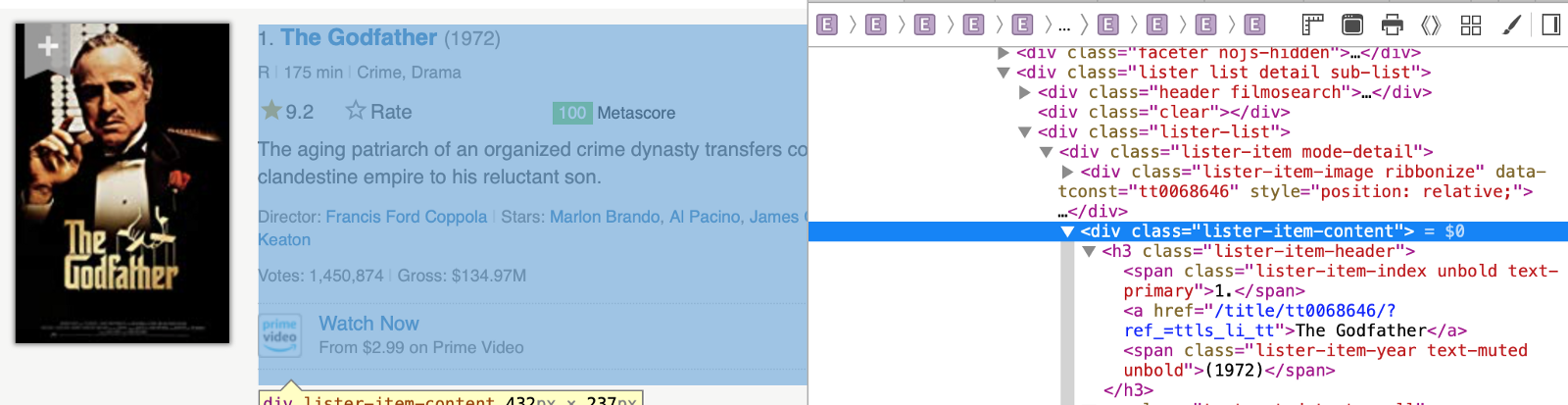
<h3> tag specifies the container that holds the movie title.


<a> tag specifies where we can extract the string, The Godfather.


Create a for loop, and use soup.findAll('h3',{'class':'lister-item-header'}) to return every line of code that stores the movie title into a list. I highlighted the movie titles to make it easier to read.


Next, we iterate through the loop and use soup.find('a', href=True).get_text() to extract the strings. Lastly, create an empty list and store the strings in it.
movie_title = []
for title in soup.findAll('h3', {'class':'lister-item-header'}):
titles = title.find('a', href = True).get_text()
movie_title.append(titles)Next, modify the code above to extract the ratings.
Ratings


I have highlighted the tag and class for you. Since the ratings are decimals, make sure to store the data as a float variable.
Genres


There are multiple ways of writing code to extract information. Here is an example of extracting genres without using multiple tags. We can specify the exact tag and class that contains ‘Crime, Drama’ and extract the string.
genre_list = []
for genre in soup.findAll('span', attrs= {'class':'genre'}):
genre = genre.get_text()
genre_list.append(genre.strip())Next, modify the code above to extract runtimes.
Runtime

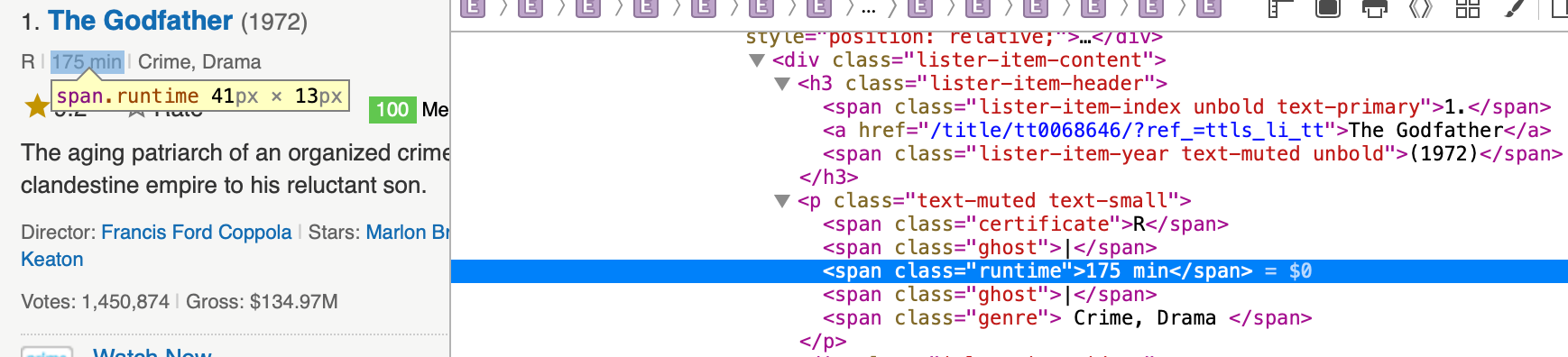
Saving it as a DataFrame
Pandas DataFrame makes it easy for us to scrape data and analyze it. We will pass each item as a dictionary.
Import the built-in python library pandas
import pandas as pdThe dictionary keys are the columns and each list is the value associated with column.
topmovies = pd.DataFrame({
‘Movie Title’: movie_title,
‘Rating’: rating_list,
‘Genre’: genre_list,
‘Runtime’: runtime_list
})
print(topmovies)Once you have ran your program, this is what the output should look like:

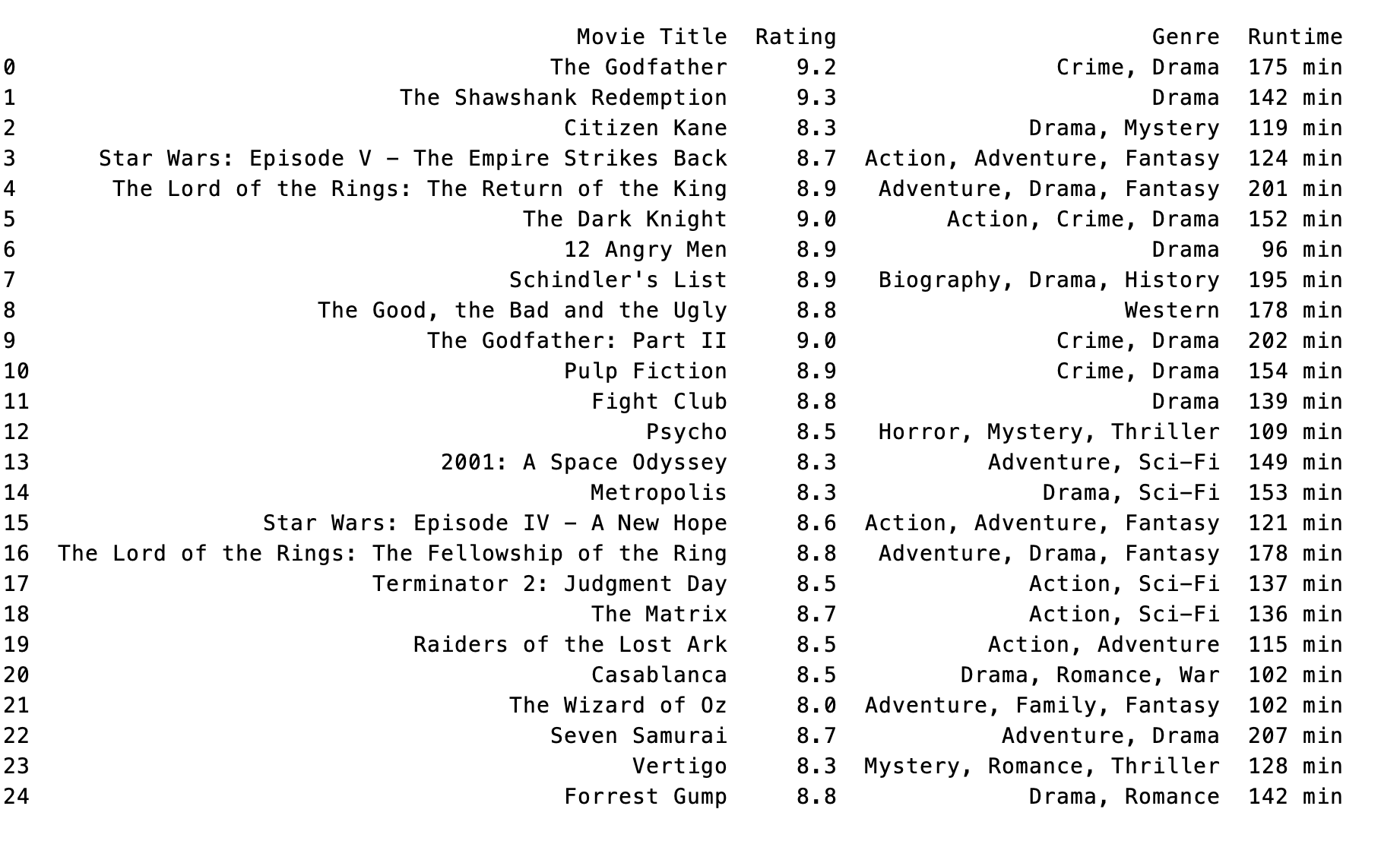
Important Notes
1. Read through the website’s Terms and Conditions to see if it’s legal to scrape data from the webpage.
2. You can cause the website to break down if you download data too fast.
python
tutorial
webscraping
beautifulsoup