Bias and Variance in Machine Learning
27 December, 2022
4
4
1
Contributors

Introduction
What is Bias?
Different Types of Biases
1.
Sampling bias: Sampling bias occurs when the data used to train a model is not representative of the entire population. For example, if a model is trained on data from a particular geographic region, it may not generalize well to other regions. Sampling bias can lead to high bias in the model, as it may consistently under or overestimate the true values of the data.
2.
Selection bias: Selection bias occurs when the data used to train a model is not randomly selected from the population. This can happen when the data is self-reported or volunteered, as it may not be representative of the entire population. Selection bias can lead to high bias in the model, as it may not accurately capture the underlying patterns in the data.
3.
Data imbalance: Data imbalance occurs when there is a disproportionate number of examples for different classes in the data. For example, if a model is trained on data with a large number of negative examples and a small number of positive examples, it may be biased towards predicting negative outcomes. Data imbalance can lead to high bias in the model, as it may not accurately capture the underlying patterns in the data.
4.
Overfitting: Overfitting occurs when a model is too complex and sensitive to small changes in the data, leading to poor generalization to new, unseen data. Overfitting can lead to high variance in the model, as it may perform well on the training data but poorly on new data.
What is Variance?
Different Types of Variances
1.
Data variance: Data variance occurs when the data used to train a model is highly variable, leading to large fluctuations in the model's predictions. This can be caused by the presence of noise or outliers in the data, or by the data is highly dependent on the specific context or conditions in which it was collected.
2.
Model variance: Model variance occurs when a model is highly sensitive to small changes in the data, leading to large fluctuations in its predictions. This can be caused by using a complex model with many parameters, or by using a model that is not well suited to the task at hand.
3.
Sampling variance: Sampling variance occurs when the data used to train a model is not representative of the entire population, leading to large fluctuations in the model's predictions. This can be caused by using a small sample of data, or by using data that is not randomly selected from the population.
4.
Selection variance: Selection variance occurs when the data used to train a model is not randomly selected from the population, leading to large fluctuations in the model's predictions. This can be caused by using self-reported or volunteered data, or by using data that is not representative of the entire population.
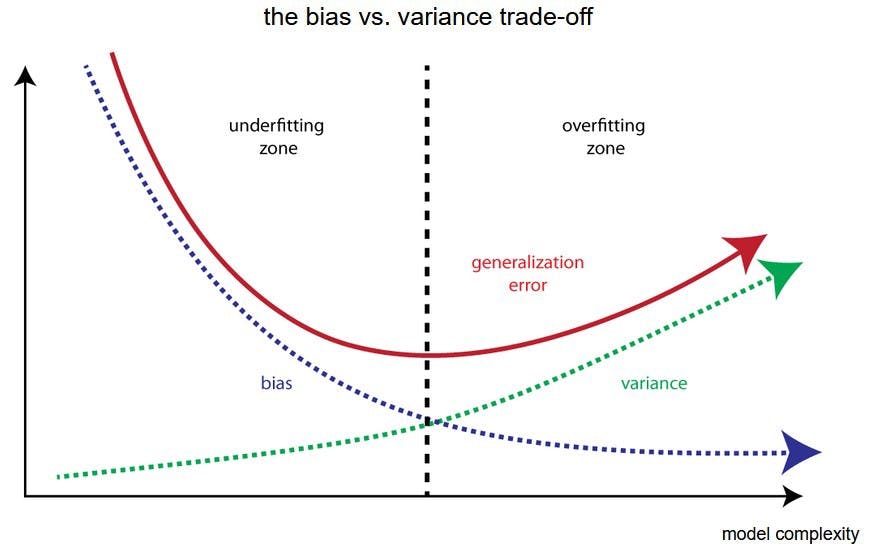
How to find the right balance between bias and variance?
Various techniques to understand and adjust bias and variance
1.
One common approach is to adjust the complexity of the model itself. For example, using a more complex model with more parameters may reduce bias but increase variance, while using a simpler model with fewer parameters may increase bias but reduce variance.
2.
Another technique is to use regularization, which is the process of adding constraints to a model to prevent overfitting. This can be done by adding a penalty term to the objective function that is being optimized, which encourages the model to prefer simpler solutions.
3.
Cross-validation is another technique that can be used to evaluate the bias and variance of a model. This involves dividing the data into multiple sets and training the model on one set while testing it on the others. This can help identify the optimal complexity of a model by comparing the performance of the different sets of data.
1.
One approach is to collect more data. This can help reduce bias by providing a larger and more representative sample of the data, and it can also help reduce variance by providing more examples for the model to learn from. However, it is important to ensure that the additional data is high quality and relevant to the task at hand.
2.
Another strategy is to use ensembling, which is the process of combining the predictions of multiple models to improve the overall accuracy. This can be done by training multiple models on different subsets of the data and then averaging their predictions, or by training a single model on the predictions of multiple other models. Ensembling can help reduce variance by smoothing out the predictions of individual models, but it can also increase bias if the models being combined are biased themselves.
3.
Finally, feature engineering is the process of designing and selecting the input features that are used to train a model. Good feature engineering can help reduce bias by providing the model with relevant and informative input data, and it can also help reduce variance by removing noise and irrelevant information from the data.
What is the bias vs variance trade-off?